Believe it or not.
Apologies for the delay in creating this post, but I recently moved from the UK to New Zealand, starting a new job at the same time, so I have been somewhat distracted!
As the eternal hunt for a scientifically validated OBE in an NDE continues (slowly), and the realisation dawns on researchers that it may be many years before such an event occurs, the community is required to continue to rely on human validation. This paper is an attempt to create a tool that seeks to objectively measure the reliability of these “humanly verified” NDEs. Thanks Paul for alerting us to this article

Scale Construction
The development of the vNDE evidential strength scale followed the Delphi Method using feedback from a panel of experts. The process involved circulating a draft scale among 11 experts for review and revision in two rounds, allowing time for detailed input and fostering consensus. Initially, the scale covered seven criteria; after expert discussion and consensus (80% agreement), the final version included eight well-defined criteria, each designed to rigorously assess aspects of the near-death experience and its verification.
Scale Criteria
The final scale contains eight items, covering critical aspects such as the timing of the investigation, the experiencer’s physical and medical state, the occurrence of cardiac or respiratory arrest, the degree of third-person verification, possibility of sensory explanations, the number of verified and erroneous perceptions, and the clarity of recalled perceptions. For each criterion, evaluators are required to provide both a rating and a written justification, lending qualitative depth to the scoring process.
Scale Scoring
Scores from each of the eight items are summed, resulting in a total between 0 and 32. This total score is then mapped to one of four predetermined levels of evidential strength (very low, low, moderate, or strong) aligned with the quartiles of possible scores. The highest tier, “strong,” requires not only a high total score but also a high rating in third-person verification, ensuring robust evidential support.
Scale Validation
The vNDE Scale was validated by having 13 experts and three AI language models (ChatGPT v.4, Gemini Pro, and Mistral Medium 3) independently apply it to 17 potential veridical near-death experiences (vpNDEs) detailed in nine peer-reviewed papers (most people would be familiar with these cases that have been discussed here and on the web extensively). The selection of cases was based on strict inclusion criteria, ensuring each paper provided sufficient detail and had undergone peer review. AI raters were included to assess the feasibility of automating the scale’s application and to help counterbalance possible human biases, particularly where personal beliefs could influence scoring. Out of 13 experts, 11 completed the evaluations (with two collaborating on a joint response), while the AI models followed a standardised prompt to apply the scale to each case using the relevant sections of the papers.
My thoughts
In summary the vNDE scale they created had 8 different evidential criteria, each with their own rating scale (from 1-4), which contributed to an overall score (max 32) reflecting the quality of the evidence supporting the veracity of the OBE within an NDE.
Given the baseline requirement of the cases being presented in peer reviewed journals, and also the requirement for an independent witness, the quality is already higher than many. However, this scale refines things further to determine if the sum of evidence reported and presented is strong or not in relation to the NDE being reliable evidence of an independent consciousness or not.
Below is the kind of output that was generated:
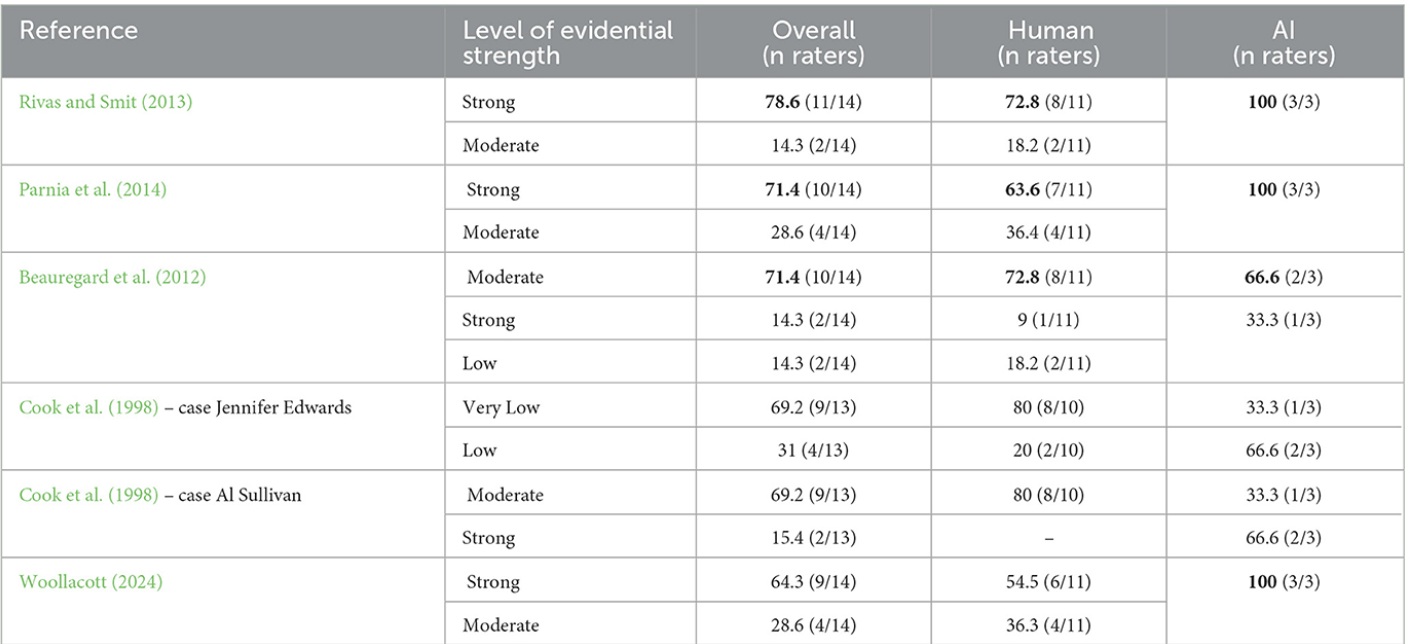
What is notable is that in the majority of cases a consensus of specific strength was not reached (e.g. strong vs moderate). However when adjacent levels were considered (e.g. strong or moderate), things improved. There was reasonable consensus within the AI models, and between AI and humans, although some wild discrepancies as well.
Given the fact that the tool failed to create consistent precise consensus between the expert assessors, it is clear that the ability to quantify the levels of strength is not quite objective enough, and allows for subjective inter-assessor interpretation. It also shows (once again) that AI while promising, cannot be fully relied upon to replace humans, even for a task that it should be ideally qualified to perform.
Having said that, in the absence of an OBE verified using electronic equipment like in AWARE II, this is about as good as it gets for now. Further refinement of this tool creating better alignment between expert assessors will no doubt lead to a fully validated tool that can be incorporated in future research.
The other outcome of this study is the fact that AI and the expert panel agreed that the three top cases in the table above had strong evidence to support the validity of the OBEs. We should bank that for now and use these three as exemplary examples of well documented OBEs with third party witnesses. I am glad that the AWARE I OBE is in this group.
Lastly I just wanted to cover a recent poster presented by the Parnia lab at AHA recently (thanks Z). It is somewhat related to the previous article, so worth shoving in here:

Summary of Abstract:
Background: About 10% of cardiac arrest survivors experience vivid Recalled Experiences of Death (RED) marked by clear awareness and a sense of life review, which can enhance quality of life. Although often dismissed as hallucinations or dreams, this study uses Natural Language Processing (NLP) to objectively distinguish RED from dreams and drug-induced states.
Hypothesis: NLP can differentiate RED accounts in cardiac arrest patients from other altered states based on thematic content, informing our understanding of consciousness during clinical death.
Methods: Researchers analyzed 3,700 anonymized first-person narratives: 1,245 RED, 1,190 dream, and 1,265 drug-induced reports, using keyword filtering and transformer-based models (Longformer for narrative classification; BERT for RED theme identification).
Results: The Longformer model achieved 98% validation F1-score and 100% holdout accuracy, accurately classifying all holdout drug narratives without needing substance names. The BERT model identified RED-specific themes with 90% validation and 87% holdout F1-scores.
Conclusion: Transformer-based NLP can effectively distinguish RED from other experiences, revealing distinct and structured patterns, and providing an objective method for analyzing survivor narratives and related psychological outcomes.
My Interpretation
Parnia’s utilisation of artificial intelligence to analyse the narrative content of two distinct types of experiences—Recalled Experiences of Death (RED) and those induced by drugs or dreams—demonstrates that AI is capable of reliably distinguishing between authentic near-death experiences and other altered states. Although the outcomes are inherently influenced by the subjective prompts provided to the AI models, the findings nonetheless reinforce the view that REDs are unique and fundamentally different in character from both “natural” and “artificial” hallucinations or experiences.
Moreover, this approach contributes to the development of more objective methodologies for differentiating between these reports. By leveraging AI as a tool for analysis, it becomes possible to more clearly separate genuine REDs from other experiences, supporting the argument that these phenomena possess distinguishing features that set them apart from ordinary dreams or drug-induced perceptions.
As always, if you haven’t already, please buy one of my books:





